Beyond the Chatbox: A 2026 Engineering and Business Guide to the “Big Six” AI Models
If you’re still picking your AI model based on vibes and Twitter hype, you’re leaving money on the table. The landscape in early 2026 has matured past the “which chatbot is smartest?” phase and moved squarely into “which model integrates best with what I actually do?”
I’ve spent the past year building scraping pipelines, outreach engines, content workflows, and acquisition tools across multiple AI stacks and most of it is just vibe coding. This is what I’ve learned, not from benchmarks alone, but from shipping real work.
This guide is for developers, content architects, and anyone running digital operations who needs to stop treating AI like a novelty and start treating it like infrastructure.
The 2026 “Intelligence Gap”: Integration Over Intelligence
Here’s the uncomfortable truth about the current market: raw intelligence scores have converged. The top five models all score within spitting distance of each other on most academic benchmarks. What hasn’t converged is how each model fits into a production workflow.
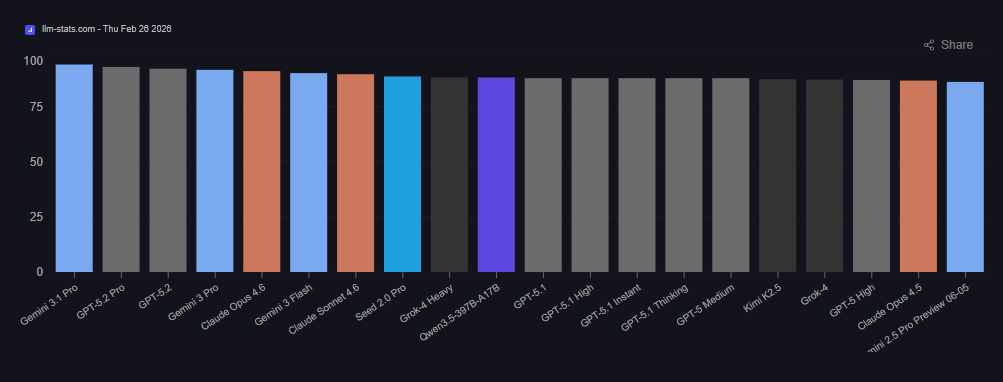
Source: LLM Stats
We’re seeing a clear split between models that still operate as glorified chatboxes (you type, it replies, you copy-paste) and models that have become genuine operating environments, where you can research, draft, code, and deploy without ever leaving the interface.
The question isn’t “who’s smartest?” anymore. It’s “who wastes the least of my time?”
1. The High-Stakes Coding Duel: Claude vs. Gemini vs. GPT-5.2
For developers, 2026 is the year the gap between “working code” and “maintainable architecture” became impossible to ignore.
Claude 4.5 Sonnet / Opus 4.6 — The Architecture-First Approach
Claude’s coding story is really two stories. Sonnet 4.5, released September 2025, hit 77.2% on SWE-bench Verified, the highest score any model had achieved at the time. Opus 4.5 followed in November and pushed that to 80.9%. Then in February 2026, Opus 4.6 arrived with a 1M-token context window, agent team coordination, and a 79.2% SWE-bench score (with thinking enabled).
But the headline numbers aren’t what matter most here. What matters is Claude Code, the CLI tool that has quietly become the best developer experience in the market. It performs an architectural scan of your project (via a CLAUDE.md file) before making changes, meaning it understands your project’s conventions, not just its syntax. The 2.0 release added automatic checkpoints (rollback any AI change instantly), subagent delegation for multi-file edits, and IDE integration through hooks.
In practical terms: Claude models prioritize DRY principles and structural consistency better than anything else available. If you’re maintaining a production codebase and you care about code review overhead downstream, this is where you want to be.
Where it falls short: Sonnet 4.5’s 200K context window means that for truly massive monorepos, where you need 500K+ tokens of context loaded simultaneously, you’ll hit walls that competitors don’t have. (Opus 4.6 addresses this with its 1M window, but at a higher price point.)
Gemini 3 Pro — The Context Monster
Gemini 3 Pro launched in November 2025 and its defining feature is the 1M-token context window with 64K tokens of output. That’s roughly 1,500 pages of text or 50,000 lines of code processable in a single request. No chunking, no summarization hacks, no “feed it in batches” workarounds.
Google has leaned hard into agentic capabilities with Gemini 3, the model can invoke browser control, shell execution, and function calling directly from within its reasoning loop. The “Deep Think” mode pushes reasoning on complex problems even further, posting a 93.8% on GPQA Diamond and 45.1% on ARC-AGI-2 (with code execution).
Where it shines: Repository-level refactors where you need the model to hold your entire documentation, legal history, and codebase in memory simultaneously. Feed it everything and it won’t “forget” a variable declared 2,000 lines ago.
Where it falls short: Gemini 3 Flash scored 76.2% on SWE-bench Verified…strong, but trailing Claude’s Sonnet 4.5. The raw coding muscle isn’t quite at the same level. The advantage here is contextual memory, not surgical precision.
GPT-5.2 — The Orchestrator
Released December 2025, GPT-5.2 brings a 400K context window with 128K output tokens and three operating modes: Instant (no reasoning overhead), Thinking (chain-of-thought), and Pro (maximum intelligence, maximum cost). The Codex variant, launched January 2026, is purpose-built for agentic coding with context compaction, scoring 56.4% on SWE-Bench Pro and 64.0% on Terminal-Bench 2.0.
GPT-5.2’s real value isn’t as a standalone coder, it’s as an orchestrator. Through Model Context Protocol (MCP), it bridges your calendar, Slack, code sandbox, and CRM in a single session. It acts less like a coding assistant and more like a project manager that can also write code.
Where it falls short: Latency. In early 2026, the system overhead from MCP orchestration is noticeable, especially compared to Claude Code’s lean terminal-first approach. For high-speed, heads-down coding sessions, GPT-5.2 often feels like the slowest link in the chain. And watch out for the hidden “reasoning token” tax, the invisible thinking tokens get billed at the output rate of $14/M, quietly inflating costs on complex queries.
The Verdict on Coding
For almost all of 2025, I used ChatGPT for vibe coding. With absolutely no background in coding and programming, it was like a dream come true but also frustrating at times. I was able to create scrapers and outreach pipelines and agents connecting Make.com with ChatGPT but it took someone like me hours of back and forth.
Come 2026, I switched to Claude and Gemini and boy did it feel like a completely different ball game. My first interaction with Claude was with Opus 4.5 and it pretty much created wordpress themes in a single go. However I was jolted back to reality when I hit the daily usage limit within 3 hours of subscribing to the pro plan.
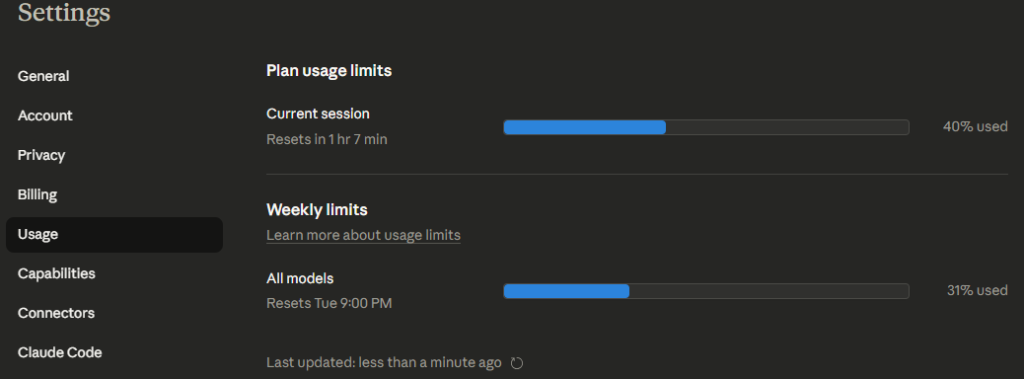
I only hit usage limits with ChatGPT once or twice but their router logic auto switches to a cheaper model to make sure your work doesn’t stop. Claude however does not let you work unless the session resets or you buy extra credits. This was kind of a rude awakening because in my mind, Claude went from the epic best thing to oh no, I have to deal with usage limit anxiety now. The solution was to either be very efficient in prompting, which is difficult for anyone who converses with LLMs or to sign up with Gemini. So that’s what I did, the basic tier of Gemini is good enough and it removes the usage limit issue.
So the best way to go about this is to use Claude (Sonnet 4.5 or Opus 4.6) for day-to-day development, PR generation, bug fixing, and anything where code quality matters more than context size. Use Gemini 3 Pro when you need to reason over massive codebases, documentation sets, or multi-file refactors that exceed 200K tokens. Use GPT-5.2 Codex when your workflow requires tool orchestration, pulling data from external systems, running sandboxed scripts, and coordinating multi-step pipelines.
2. The Research and Content War: Citations vs. Speed vs. Cost
High-authority SEO in 2026 lives and dies on provable truth. Google’s E-E-A-T signals (Expertise, Experience, Authoritativeness, Trustworthiness) now function as a hard filter, not a suggestion. If your content reads like regurgitated chatbot output, no original data, no first-hand perspective, no verifiable claims then it gets buried under AI Overviews.
Claude’s Research Mode — The Citation Standard
Claude’s deep research capability is currently the gold standard for producing “whitepaper-quality” content. It doesn’t just search the web, it browses multiple sources, synthesizes findings, and provides inline citations that are actually clickable and relevant. For anyone producing long-form analytical content (investment analysis, market reports, technical guides), this matters enormously. The output reads like research, not like a chatbot summarizing its training data.
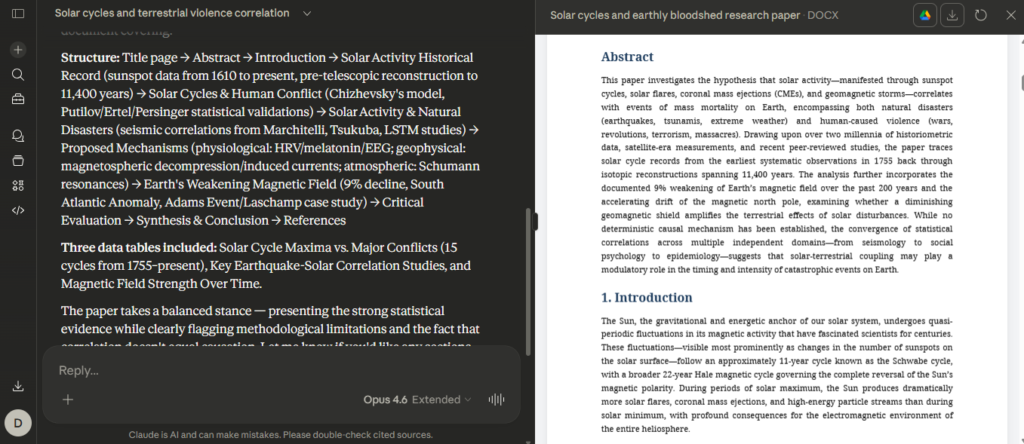
I have tested creating multiple research papers and honestly, Claude has been better than both GPT and Gemini at this. However the key here is to know what you are looking for. You cannot just tell Claude your topic and expect an academic paper that can stand full scrutiny. You must have the whole framework in mind and guide Claude through your prompt, just like a research assistant would. The key here is not to look at Claude or any other LLM as an AI slave but rather as an assistant, who is really good at the job.
Grok 4.x — The Real-Time Pulse
Grok 4 (and the upcoming 4.20 variant) has the fastest “event-to-answer” latency in the market, largely because it indexes X (formerly Twitter) data and the live web simultaneously. xAI’s access to the full X firehose, roughly 68 million English tweets (or posts?) per day, gives it a real-time sentiment layer no other model can match.
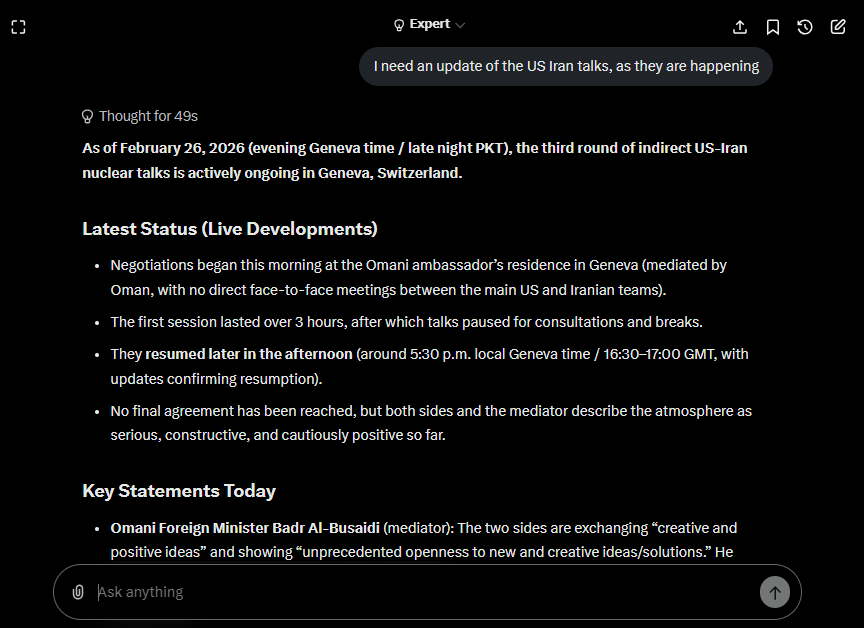
The above screenshot was taken when the Us – Iran negotiations were going on in Geneva. Grok shines at real time event updates, other models simply cannot come close to Grok’s awareness levels.
For breaking news SEO, real-time market analysis, or trend detection, Grok is unmatched. In the Alpha Arena trading simulation, an early Grok 4.20 checkpoint achieved approximately 10-12% average returns while competing AI models lost money, a strong signal that real-time data processing translates into actionable intelligence.
The brokerage use case: For identifying “off-market” opportunities, a founder tweeting about moving on from their project, social signals indicating a niche site is winding down — Grok catches signals that traditional web search misses entirely.
Qwen3-Max — The Budget Workhorse
Alibaba’s Qwen3-Max won’t win glamour awards, but at $1.20 per million input tokens (with further discounts through batch processing and caching), it’s the most cost-effective proprietary option for high-volume content generation. The model supports 256K tokens of context and handles multilingual content across 100+ languages.
The play here isn’t to use Qwen as your final output, it’s to use it as your first-pass engine. Generate drafts at near-zero cost, then move them to Claude or a human editor for fact-checking, tone adjustment, and de-slopping.
3. The Agentic Shift: Delegation Over Conversation
The biggest paradigm shift of 2026 isn’t a new model, it’s the realization that we’ve moved from “chatting with AI” to “delegating to AI.” The models that win are the ones that can take a task, break it into steps, use tools, and come back with a completed deliverable.
ChatGPT Agent Mode
OpenAI’s approach is the “orchestrator” model. Using MCP, ChatGPT can see your calendar, ping your Slack, run Python in a sandbox, clean a lead list, and draft a follow-up email, all in one session. The breadth of integrations is impressive.
The trade-off is overhead. Each tool call adds latency, and for workflows that need to move fast (like real-time lead qualification during a scraping run), the accumulated delays can make ChatGPT feel sluggish compared to a purpose-built script.
Qwen-Agent (Open Source)
For teams that value data sovereignty and speed, Alibaba’s open-source Qwen-Agent framework is the power play. You can build a local, self-hosted browser assistant that scrapes, plans, and executes workflows, like outreach to site owners without sending your proprietary lead data to anyone’s servers.
This matters most for acquisition operations where your lead lists, valuation models, and outreach templates are competitive advantages. Running them through a third-party API creates data exposure you might not want.
Claude Code as an Agent
Claude Code deserves mention here. With the 2.0 release, it can operate autonomously for 30+ hours without human guidance, Anthropic’s internal tests showed it building entire applications, standing up databases, purchasing domains, and completing security audits over full-day sessions. The subagent architecture lets it delegate subtasks to specialist instances, making it the most capable single-agent coding system available.
2026 Cost-Efficiency Matrix
For any business scaling content or outreach, input token cost is your primary overhead. Here’s the current pricing landscape (as of February 2026):
| Model | Input ($/1M tokens) | Output ($/1M tokens) | Context Window | Best Workflow Fit |
|---|---|---|---|---|
| Grok 4 Fast | $0.52 | $1.30 | 2M | Real-time analysis, social signals, high-volume queries |
| Qwen3-Max | $1.20 | $6.00 | 256K | Bulk drafting, lead scoring, multilingual content |
| GPT-5.2 | $1.75 | $14.00 | 400K | Multi-tool orchestration, agentic workflows |
| Gemini 3 Pro | $2.00 | $12.00 | 1M | Large-document analysis, workspace-native operations |
| Claude 4.5 Sonnet | $3.00 | $15.00 | 200K | Production coding, final-draft editing, research |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M | Complex agentic tasks, agent teams, flagship intelligence |
What the Table Doesn’t Tell You
GPT-5.2’s hidden cost: The “reasoning tokens” (invisible thinking tokens billed at the $14/M output rate) can quietly double or triple the cost of complex queries. OpenAI offers a 90% discount on cached input tokens ($0.18/M), which is a lifesaver for apps with repetitive system prompts — but you have to architect for it.
Claude’s caching advantage: Prompt caching significantly reduces costs for workflows that re-use the same large context (like a project’s CLAUDE.md file or a standard analysis template).
Grok’s deceptive cheapness: The per-token pricing is outstanding, but the ecosystem and tooling are still immature compared to Claude or OpenAI. You’ll spend more developer hours building integrations that are one-click solutions elsewhere.
Qwen’s batch discount: Alibaba offers a 50% discount on asynchronous batch jobs. If your work isn’t time-sensitive (overnight content generation, bulk lead scoring), this makes Qwen effectively $0.60/M input — hard to beat at any scale.
Strategic Stacks: Who Should Use What
For Lead Discovery and Marketing
- Lead Discovery: Use Grok for real-time social signals — founders tweeting about exits, niche forums discussing site sales, sentiment shifts in specific industries.
- Site Analysis: Use Gemini 3 Pro to ingest bulk HTML scrapes, analytics exports, and documentation to assess site health and monetization potential. The 1M context window means you can feed in an entire site’s content structure in one pass.
- Outreach and CRM: Use GPT-5.2 Agent Mode for scheduled, personalized email drafting and CRM logging across multi-campaign workflows.
- Custom Tooling: Use Claude Code to build and maintain the scraping pipelines, Google Sheets integrations, and automation scripts that tie the stack together.
For Content Operations and SEO
- First Drafts: Use Qwen3-Max for volume. At $1.20/M input tokens, you can generate dozens of article drafts for pennies.
- Research and Polish: Move drafts to Claude (Research Mode for fact-checking, Sonnet/Opus for tone and quality). Claude’s citation system gives you verifiable sourcing that holds up under editorial scrutiny.
- SEO Intelligence: Use Gemini to cross-reference with Google’s own search trends. Being native to Google’s ecosystem gives it unique insight into what’s ranking and why.
- Trend Monitoring: Use Grok to catch emerging topics before they hit mainstream search volume. The X data firehose is effectively a leading indicator for search trends.
The “AI Slop” Problem and How to Beat It
Google’s 2026 ranking algorithm has gotten aggressive about detecting and penalizing AI-generated content that lacks substance. Here’s what separates content that ranks from content that gets buried.
What Gets Buried
Generic prose with no original screenshots or data visualizations. No unique data points or proprietary analysis. No first-hand anecdotes or experience-based claims. Excessive hedging language (“it’s important to note that…”). Perfectly balanced “on one hand / on the other hand” structure with no actual opinion. Suspiciously comprehensive coverage of every sub-topic with no depth on any of them.
What Ranks
Original research with your own data. Specific tool comparisons based on actual usage, not paraphrased spec sheets. Clear opinions backed by reasoning, even controversial ones. “Who this is NOT for” sections (AI slop never tells readers not to buy something). Screenshots from your own workflow showing real results. Inline data tables with numbers you’ve gathered or calculated yourself.
The Core Irony
The models are now good enough to produce technically accurate prose, but that prose is worthless for SEO unless it’s anchored in genuine human experience. Use AI to accelerate your research, structure your arguments, and polish your writing but the core insights, the opinions, and the “I tried this and here’s what happened” anecdotes have to come from you.
Who This Guide Is NOT For (see what we did there)
If you’re a casual user who just needs a chatbot for daily questions and occasional writing help, this guide is overkill. Stick with whichever model your current subscription gives you, they’re all good enough for general use, and the differences only matter at scale.
If you’re building a hobby project and cost is your primary concern, skip the premium models entirely. Qwen’s open-source variants or DeepSeek can handle most tasks at a fraction of the cost, and you can run them locally.
This guide is specifically for people whose livelihoods depend on choosing the right AI infrastructure and who are losing money every month they spend on the wrong one.
What’s Coming in the Next 90 Days
The next quarter will be dense. Grok 4.20 is expected within the week (as of mid-February 2026), with significant improvements over 4.1. Gemini 3.1 Pro is reportedly imminent. GPT-5.3-Codex-Spark, an ultra-fast coding variant running at 1,000+ tokens per second on Cerebras hardware just entered research preview. And Grok 5, with a reported 6 trillion parameters, is projected for Q1 2026.
The strategic move right now isn’t to bet everything on one model. It’s to build workflows that are model-agnostic at the edges and specialized at the core. Use the cheapest model that gets the job done for bulk work, the best model for your critical path, and keep your integrations flexible enough to swap when something better arrives.
Because in 2026, something better always shows up.